A fresh look on incremental zero copy serialization
It’s been a few months since I released Müsli to the world. An experimental binary serialization framework. I’ve used it quite happily in a few projects. But there was one area which it didn’t exactly fit.
Say you have a database, a dictionary with millions of text entries and cross references. And you want to perform sporadic but fast word lookups on the command line. How do you store the database?
We might opt to reach for some neat binary serialization. But even the fastest framework takes seconds to load the data set, which just isn’t that great of a user experience for a CLI tool. This is understandable, because the job of a deserializer is broadly to take byte array and turn it into a data structure that the Rust application can use. Typically this is done by painstakingly long walk through the data and convert it to boxes or lists or other things that Rust programmers can reason about.
For millions of text entries - those boxes, lists, and other things containing millions of entries that need to be allocated, decoded, arranged, cuddled … work that inevitably takes up resources we’d rather not spend.
This is where zero-copy serialization might come in handy. Instead of loading
and processing the entire contents of the file, we might be able to map the file
as-is into the application and treat it as Rust data structures directly. In
essence a &[u8] to &T translation layer. Take a slice, return a reference to
some type we can work with.
Now I can see the look on your face, isn’t that wildly unsafe?
Well yes. Of course it. Super duper unsafe1. But it doesn’t
have to be unsound.
In this article I’ll discuss what it takes to soundly map data directly onto
structures which are defined in Rust. And while doing so introduce a library I
spent the last couple of weeks working on to make that easier. Namely
musli-zerocopy.
There are two directions I want to discuss, soundly converting a data structure into a a slice, and soundly converting a slice into the reference of a data structure.
As a basis there are a few things we should know about &T.
- The reference has to point to data which is aligned with respect to
T; - All bytes in
Texcept for padding (we’ll talk about this later) have to be initialized to some value, and; - The bit pattern that is stores at
&Thas to be valid forT.
So if we take it in order. To convert a rust type into an slice we will have to cover the topics of The #[repr(Rust)] representation and alignment and padding. After that when when we discuss converting a slice back into a Rust type we also need to cover the notion of legal bit patterns.
So… onwards!
The #[repr(Rust)] representation
Rust provides very few guarantees what the layout of a data structure should be. While this might seem like a nuisance at first, it’s actually very helpful.
When Rust sees a data structure like this:
struct Yoke {
a: u8,
number: u32,
b: u8,
c: u8,
d: u8,
}
assert_eq!(std::mem::size_of::<Yoke>(), 8);
The size of the structure is 8.
If we switch to #[repr(C)], which has a well-defined layout, the size of the
structure increases to 12.
#[repr(C)]
struct Yoke {
a: u8,
number: u32,
b: u8,
c: u8,
d: u8,
}
assert_eq!(std::mem::size_of::<Yoke>(), 12);
This is because #[repr(C)] is required to order the fields per their
definition order, and respect each fields alignment its alignment is the
multiple of a memory address that a specific structure wants to be located on,
and for u32 that is 4. To achieve this Rust moves the location of the number
field. This causes some extra unused space to be used in the struct called
padding.
Note An alignment is required to be a power of two, and
Yokeitself inherits the largest alignment of its fields which ensures that as long asYokeis aligned in memory, so too willnumber.
#[repr(Rust)] on the other hand is free to re-arrange the fields. Yoke might
be rewritten to this:
struct Yoke {
number: u32,
a: u8,
b: u8,
c: u8,
d: u8,
}
Which neatly means that the alignment of all the fields is respected, and we save space.
In order to ensure that a data structure is valid, we can’t have Rust move
things around without telling us. So we’re obligated to use #[repr(C)]. To do
this correctly we need to delve deeper into the next topic. A tour into
alignment and padding.
A tour into alignment and padding
When Rust sees a structure like this:
#[repr(C)]
struct Yoke {
a: u8,
number: u32,
}
It internally treats it as something like this:
#[repr(C)]
struct Yoke {
a: u8,
_pad1: [u8; 3],
number: u32,
}
So if we copy Yoke byte-by-byte, we will catch the value of _pad1 as well.
This causes a problem, because these values are not initialized.
First, padding bytes are considered uninitialized.
This is illustrated perfectly by our good friend Miri with this snippet:
use std::slice;
use std::mem::size_of;
#[repr(C)]
struct Yoke {
a: u8,
number: u32,
}
fn main() {
let link = Yoke {
a: 0x01,
number: 0x02030405,
};
let bytes = unsafe {
let ptr = (&link as *const Yoke).cast::<u8>();
slice::from_raw_parts(ptr, size_of::<Yoke>())
};
// Touch the first byte in the padding between a and b.
let b1 = bytes[1];
}
error: Undefined Behavior: using uninitialized data, but this
operation requires initialized memory
--> src/main.rs:21:14
|
21 | let b1 = bytes[1];
| ^^^^^^^^ using uninitialized data, but this
operation requires initialized memory
While Miri strictly speaking isn’t authoritative on all matters, it is right here. So does this mean that there’s nothing we can do?
Well yes, we can initialize the padding ourselves. For example, directly where
Yoke is stored:
use std::slice;
use std::mem::size_of;
#[repr(C)]
struct Yoke {
a: u8,
number: u32,
}
fn main() {
let mut link = Yoke {
a: 0x01,
number: 0x02030405,
};
unsafe {
let ptr = (&mut link as *mut Yoke).cast::<u8>();
// Zero out three bytes of padding at offset 1
ptr.add(1).write_bytes(0, 3);
}
let bytes = unsafe {
let ptr = (&link as *const Yoke).cast::<u8>();
slice::from_raw_parts(ptr, size_of::<Yoke>())
};
dbg!(&bytes);
}
If that seems like too much,
musli-zerocopyhas a shorthand for the above called initialize_padding, so the above becomes.
Deserialization seems easy in comparison. As long as we know that the buffer we’re using is initialized.
use std::mem::size_of;
#[derive(Debug)]
#[repr(C)]
struct Yoke {
a: u8,
number: u32,
}
fn main() {
let bytes: [u8; size_of::<Yoke>()] = [1, 0, 0, 0, 5, 4, 3, 2];
let link: &Yoke = unsafe { &*(&bytes as *const u8).cast::<Yoke>() };
dbg!(&link);
}
But this is subtly wrong. As mentioned in the beginning &T has to reference a
T that is stored at an aligned memory location:
error: Undefined Behavior: accessing memory with alignment 2,
but alignment 4 is required
--> src/main.rs:12:25
|
12 | let link = unsafe { &*(&bytes as *const u8).cast::<Yoke>() };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| accessing memory with alignment 2,
| but alignment 4 is required
The nasty part here is that if we’re unlucky, we might’ve ended up loading
Yoke from an aligned memory address on the stack and wouldn’t notice this
issue with Miri.
So for deserialization we have at least the problem of alignment. Luckily we have tools for that. Including this hack:
use std::mem::size_of;
#[derive(Debug)]
#[repr(C)]
struct Yoke {
a: u8,
next: u32,
}
// Align `T` with respect to `Yoke`.
#[repr(C)]
struct Align<T>([Yoke; 0], T);
fn main() {
let bytes: &Align<[u8; size_of::<Yoke>()]> = &Align([], [1, 0, 0, 0, 5, 4, 3, 2]);
let link = unsafe { &*(&bytes.1 as *const u8).cast::<Yoke>() };
dbg!(&link);
}
This stems from the fact that the alignment of the vector matches the largest
alignment of its elements. So even if the vector inside of Align is
zero-sized, it still forces the whole structure to be aligned by Yoke. Since
it’s zero-sized, we must conclude that the subsequent T is stored at the same
location, which luckily for us now is aligned by Yoke.
This is a neat hack. And I do use it in some places to store the output of
include_bytes! in an aligned buffer. But as a tool it is rather clunky. We
have to decide on the alignment up front at compile time.
If only there was a data structure that understand how to align its memory…
Ah well, that’s for later. First we need to convert another problem with deserialization. What exactly constitutes a legal bit patterns for a structure?
Legal bit patterns
Let’s revisit Yoke, but change the second field to be a char instead of a
u32. Of course we’ll also rename it, because otherwise it would be confusing.
#[derive(Debug)]
#[repr(C)]
struct Yoke {
a: u8,
character: char,
}
If we try to cast a byte array into this structure, we need to make sure that
all bit patterns are inhabitable by it. But what bit patterns can a char
inhabit?
Reading the rust reference and char::from_u32 we can intuit that a char
is 4 bytes wide, but cannot inhabit all possible bit patterns that those 4 bytes
can represent.
Miri seconds this:
struct Align<T>([char; 0], T);
fn main() {
let values: Align<[u8; 4]> = Align([], 0x110000u32.to_ne_bytes());
let c = unsafe { *(values.1.as_ptr() as *const u8).cast::<char>() };
}
|
5 | let c = unsafe { *(values.1.as_ptr() as *const u8).cast::<char>() };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| constructing invalid value: encountered 0x00110000,
| but expected a valid unicode scalar value
| (in `0..=0x10FFFF` but not in `0xD800..=0xDFFF`)
This is how we’d define the legal bit pattern for any type T with a
#[repr(C)]:
- Each field must be a legal bit pattern at their corresponding offsets.
- If the type is an enum, there is a first secret field called the discriminant which determines which variant is used. Then each field of the variant has to have a legal bit pattern at their corresponding offsets.
- Padding regions are ignored.
So let’s try to write a validator for Yoke which respects all these
requirements:
use std::mem::{align_of, size_of};
#[derive(Debug)]
#[repr(C)]
struct Yoke {
a: u8,
character: char,
}
#[derive(Debug)]
enum Error {
NotAligned,
BufferUnderflow,
BadChar,
}
fn validate(bytes: &[u8]) -> Result<&Yoke, Error> {
// Check that the buffer is aligned.
if (bytes.as_ptr() as usize) % align_of::<Yoke>() != 0 {
return Err(Error::NotAligned);
}
// Check that the buffer has the right number of bytes.
if bytes.len() < size_of::<Yoke>() {
return Err(Error::BufferUnderflow);
}
// Since the first field is an u8, it can inhabit *any* bit pattern.
// Access the character field, at offset 4.
let character_ptr: *const u32 = unsafe { bytes.as_ptr().add(4).cast::<u32>() };
// Access the raw representation of character, which is a u32.
let character_raw = unsafe { character_ptr.read_unaligned() };
// Test that the raw representation is a valid character.
if char::from_u32(character_raw).is_none() {
return Err(Error::BadChar);
}
// We've inspected all fields and they've passed, so now we're good to cast the reference.
Ok(unsafe { &*bytes.as_ptr().cast() })
}
struct Align<T>([Yoke; 0], T);
fn main() {
let data = Align([], [42, 0, 0, 0, 80, 0, 0, 0]);
let link = validate(&data.1);
dbg!(link);
}
That is… a lot. And we still have to align the buffer ourself.
Making it easier
The goal of musli-zerocopy is making the above work easier while providing
high level tooling like references, slices or even other collections to build
and interact with complex data structures with ease.
This is what it looks like:
use musli_zerocopy::buf;
use musli_zerocopy::{Ref, ZeroCopy};
#[derive(ZeroCopy)]
#[repr(C)]
struct Person {
age: u8,
name: Ref<str>,
}
let buf = buf::aligned_buf::<Person>(include_bytes!("author.bin"));
let person = Person::from_bytes(&buf[..])?;
assert_eq!(person.age, 35);
// References are incrementally validated.
assert_eq!(buf.load(person.name)?, "John-John");
And this is the code that wrote author.bin:
use std::fs;
use musli_zerocopy::{OwnedBuf, Ref, ZeroCopy};
fn main() -> Result<()> {
let mut buf = OwnedBuf::new();
// Insert an uninitialized value to ensure that the person data is
// stored at offset 0.
let person = buf.store_uninit::<Person>();
let value = Person {
age: 35,
name: buf.store_unsized("John-John"),
};
buf.load_uninit_mut(person).write(&value);
fs::write("person.bin", &buf[..])?;
Ok(())
}
This takes care of padding, alignment, and validation for most Rust types which have a stable well-defined layout. We provide tools to easily build correct, rich applications leveraging zero-copy data structures. It is really fast, and should be memory safe (assuming there are no bugs or false assumptions from my part).
I also want to emphasize the focus on incremental rather than up front
validation, which ensures that startup is fast and doesn’t needlessly consume
system resources. Incremental validation means that instead of validating the
whole structure in one go, we only validate the elements which are accessed,
like with buf.load(person.name)? above.
Tackling the dictionary
To loop back to what started me down this path, this is what the index of my dictionary
currently looks like using musli-zerocopy:
use musli_zerocopy::swiss::MapRef;
use musli_zerocopy::{Ref, ZeroCopy};
use crate::{PartOfSpeech, Id};
#[derive(ZeroCopy)]
#[repr(C)]
struct Index {
lookup: MapRef<Ref<str>, Ref<[Id]>>,
by_pos: MapRef<PartOfSpeech, Ref<[u32]>>,
by_sequence: MapRef<u32, u32>,
}
This project is also what needed map. So I’ve ported
phfandhashbrown(namedswiss) to the project. The above usesswissmaps.
The index stores tens of millions of entries. Loading the same index using other
Müsli formats and validated rkyv takes a second or two while pinning a CPU
core to 100%, which actually isn’t fast enough for a CLI tool to feel
responsive.
The dictionary itself also uses a neat trick to perform string de-duplication, by referencing subsets of already stored string by their prefix if they are present. This in itself saves about 1G of space and I believe showcases what you can accomplish when you have access to granular tooling:
let input: Vec<(String, Id)> = /* .. */;
let mut buf: OwnedBuf = /* .. */;
let mut lookup = HashMap::<String, Vec<Id>>::new();
let mut existing = HashMap::<_, usize>::new();
let mut reuse = 0usize;
let mut total = 0usize;
for (index, (key, id)) in input.into_iter().enumerate() {
if index % 100000 == 0 {
tracing::info!("Building strings: {}: {key}", index);
}
total += 1;
let (unsize, substring) = if let Some(existing) = existing.get(key.as_ref()) {
reuse += 1;
(Ref::with_metadata(*existing, key.len()), true)
} else {
let unsize = buf.store_unsized(key.as_ref());
(unsize, false)
};
lookup.entry(unsize).or_default().push(id);
if !substring {
// Generate string prefixes and insert into existing map.
for (n, _) in key.char_indices() {
let mut s = String::new();
for c in key[n..].chars() {
s.push(c);
if !existing.contains_key(&s) {
existing.insert(s.clone(), unsize.offset() + n);
}
}
}
existing.insert(key.into_owned(), unsize.offset());
}
}
tracing::info!("Reused {} string(s) (out of {})", reuse, total);
I should note that construction of the dictionary is fairly time consuming, but that doesn’t matter since it’s always done ahead of time.
With this and thanks to incremental validation in musli-zerocopy, querying
through the CLI is both instantaneous and fully sound:
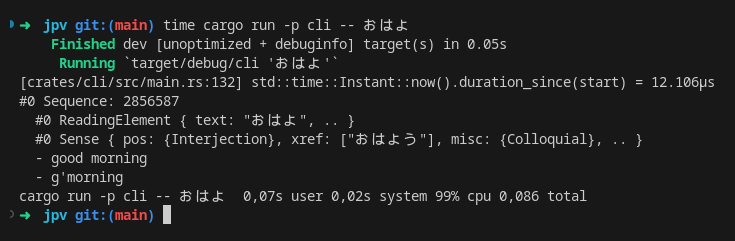
So what about this other crate?
Since people are bound to ask how this crate relates to those. musli-zerocopy
actually occupies a similar niche to zerocopy, but is fairly dissimilar from
rkyv.
This is what I write in the crate documentation:
zerocopydoesn’t support padded types2, bytes to reference conversions, or conversions which does not permit decoding types unless all bit patterns can be inhabited by zeroes3. We still want to provide more of a complete toolkit that you’d need to build and interact with complex data structures like we get through thephfandswissmodules. This crate might indeed at some point make use ofzerocopy’s traits.rkyvoperates on#[repr(Rust)]types and from this derives an optimizedArchivedvariation for you. This library lets you build the equivalent of theArchivedvariant directly and the way you interact with the data model doesn’t incur the cost of validation up front. Withrkyvit took my computer 100% of a CPU core and about half a second to load 12 million dictionary entries4, which is a cost that is simply not incurred by incrementally validating. Not validating is not an option since that would be wildly unsound - your application would be vulnerable to malicious dictionary files.
zerocopy in particular deserves a massive shout out. joshlf has done
meticulous work documenting and upstreaming (!) layout guarantees which
benefits everyone in the ecosystem.
So I think, and I hope you agree that there is some space to carve out for a
more holistic toolkit which operates directly over #[repr(C)] types. If you
do, I invite you to take the project for a spin.
-
Maybe less so once project-safe-transmute makes progress. ↩
-
This is on zerocopy’s roadmap, but it fundamentally doesn’t play well with the central
FromBytes/ToBytespair of traits ↩