In the last post I announced musli-zerocopy. In this one I’ll discuss one
of the concerns you’ll need to mitigate to build and distribute archives:
endianness.
There’s broadly two distinct ways that we organize numerical types in memory. We
either store the least significant byte first in memory, known as “little
endian”, or we store them last calling this “big endian”. This is known as the
endianness or byte order of a value in memory.
0x42 0x00 0x00 0x00 // 0x42u32 little endian
0x00 0x00 0x00 0x42 // 0x42u32 big endian
Your system has a native byte order. This is the way it expects data to be
organized in memory, so when you’re accessing a value like:
letvalue=42u32;dbg!(value);
The value 42 above is stored on the stack using one of the above layouts. Most
likely little endian.
The first version of musli-zerocopy ignores byte ordering. You’d be using the
byte order that is native to the platform you’re on. This is not much of a
problem for simple structures, since primitive fields in simple structs like
u32 natively can represent data in any byte order. Rust’s std library comes
with primitives for handling conversion, which in byte-order parlance is known
as “swapping”.
We get this value (0x2a000000, since 42 is 0x2a) because of the mismatch
between the native byte order, and the byte order of the the field. To read it
correctly, we need to swap the bytes back. All of these achieve that result on a
little-endian system:
It’s worth pondering why u32::to_be works just as well. There’s no
inherent byte order in the value being swapped. All a method like to_be
does is convert to a no-op in case the native byte order is already
big-endian. Otherwise it performs the same swapping operation.
I hope this makes it apparent why a byte-order naive application can’t process
archives correctly unless the byte order used in the archive matches the native
byte order. In order to interpret the values correctly we somehow need extra
information and careful processing.
The dictionary I built this library for demands that archives are distributed.
So one way or another it has to be portable with byte ordering in mind. In this
post I’ll detail high level strategies to deal with byte ordering, and introduce
the tools I’ve added to musli-zerocopy to make it - if not easy - manageable
to work with.
Let me make a prediction: Your system uses little endian. This is a good
prediction, because little endian has essentially won. One reason it’s a great
choice is because converting between wide to narrow types is easy because their
arrangement overlaps. To go from a u32 to a u16 you simply just read the
first two bytes of the u32 easy peasy.
None of the platforms I intend to distribute my dictionary too are big-endian.
Yet it’s still important to make sure that it works:
You don’t want to end up relying on abstractions or designs which end up being
a dead end or at worst cause bit rot down the line. Just in case.
Some formats impose arbitrary ordering demands. I’d like to be able to support
these.
Big-endian for reasons ended up being the de-facto byte order used in
network protocols.
But why is it good for values to be natively byte ordered?
Rust can generate significantly improved code when things align well with the
current platform. The following is a difference between two functions - one
which loads an [u32; 8] array using u32’s in its native byte order
(effectively copying it), and the other converted using a non-native byte order:
Despite some neat vectorization, there’s still a significant difference in code
size and execution complexity. Work is work, and work that can be avoided means
faster applications that use less power.
So how do we accomplish this? In the next four sections I’ll cover some of the
available options.
Option #1: Don’t bother
The documentation in musli-zerocopy (Reading data) mentions that there are some pieces of
data which are needed to transmit an archive from one system to another, we call
it its DNA (borrowed from Blender), these are:
The alignment of the buffer.
The byte order of the system which produced the buffer.
If pointer-sized types are used, the size of a pointer.
The structure of the type being read.
One option is to include a portable header which indicates its format and if
there is a mismatch we refuse to read the archive and bail! with an error.
We want to avoid the possibility of the application “accidentally” working since
this might cause unexpected behaviors. Unexpected behaviors at best causes an
error later down the line, at worst a logic bug leading to a security issue.
If security is an application concern, additional safeguards should be put
into place, such as integrity checking. But this is not unique to zero-copy
serialization.
useanyhow::bail;usemusli_zerocopy::ZeroCopy;usemusli_zerocopy::endian;/// A marker type for the archive indicating its endianness.////// Since this is a single byte, it is already portable.#[derive(ZeroCopy)]#[repr(u8)]enumEndianness{Big,Little,}/// The header of the archive.#[derive(ZeroCopy)]#[repr(C)]structHeader{endianness:Endianness,pointer_size:u32,alignment:u32,}letbuf:&Buf=/* .. */;letheader=buf.load_at::<Header>(0)?;ifheader.endianness!=endian::pick!(Endianness::Big,Endianness::Little){bail!("Archive has the wrong endianness");}
The pick! macro is a helper provided by musli-zerocopy. It will evaluate
to the first argument on big endian systems, and the second on little endian
systems. We’ll make more use of this below.
This is a nice alternative in case your application can download a platform
suitable archive directly. Its DNA can then be represented as a target string,
like dictionary-jp-64-be.bin.
Option #2: Care a lot
This option is a bit more intrusive, but allows for an archive to be used even
if there is a DNA mismatch. We can interact with the archive, but systems with a
mismatching byte order will simply have to take the performance hit.
In musli-zerocopy this is done by explicitly setting endianness and using
wrapping primitives like Endian<T, E>:
It isn’t strictly necessary to make use of endian-aware primitives in
musli-zerocopy, since most numerical types can inhabit all reflexive bit
patterns. It could simply be declared like this and force the bit pattern using
one of the provided conversion methods such as endian::from_le.
Maybe the most interesting alternative of them all. Store the archive in
multiple orderings and read the one which matches your platform.
🤯
In musli we can do this by storing two references in the header, and make use of
the pick! macro to decide which one to use. Due to the default value of
Data<E = Native> the correct byte order is used intrinsically after it’s been
identified since Native is simply an alias to the system ordering.
On the up, we get to interact with natively ordered data. On the down, we have
to store two versions of every byte-order sensitive data structure in the
archive. I took great care to ensure that this can be done generically in Müsli
so you at least only need to write the code which populates the archive once.
The keen eyed might note that this is a very typical time-memory trade off. We
provide the perfect representation for every platform at the cost of increasing
the space used.
In theory we could provide one per pointer-size as well, but the number of
permutations start to become … unwieldy.
Option #4: Squint hard enough and everything looks like an optimization
This strategy involves converting a stable well-defined archive into an
optimized zero-copy archive that can be loaded on subsequent invocations of your
applications. It does mean “taking the hit” if the local archive needs to be
constructed, but once it has been you’ve got the best of all worlds.
useanyhow::Context;usestd::fs;usestd::path::Path;usemusli::Decode;usemusli_zerocopy::{Ref,Buf,ZeroCopy};usemusli_zerocopy::swiss;#[derive(Decode)]structArchive{map:HashMap<String,u32>,}#[derive(ZeroCopy)]#[repr(C)]structArchiveNative{map:swiss::MapRef<Ref<str>,u32>,}letarchive=Path::new("archive.bin");letarchive_native=Path::new("archive-native.bin");if!archive_native.is_file()||is_outdated(archive,archive_native){tracing::trace!("Missing or outdated {}, building {}",archive.display(),archive_native.display());letarchive=fs::read(archive).context("reading archive")?;letarchive:Archive=musli_storage::from_slice(&archive).context("decoding archive")?;write_native_archive(&archive,archive_native).context("building native archive")?;}letbuf:&Buf=Buf::new(mmap_archive(archive_native));
One might be tempted to call this the best of all worlds, as long as you’re OK
with spending the disk space for it.
This can even be combined with Option #2, but we only
bother converting and re-saving the archive if it is the wrong byte order.
Detour: A missed enum optimization
The goal with these APIs are to ensure that any endian-aware operations impose
zero cost if the demanded byte order matches the current one. We have all the
necessary tools to muck about with the bytes of a type. Any native-to-native
swapping be they generic or not should result in a simple move, like this:
Rust decides to check the discriminant and generate a branch for each unique
variant. It then proceeds to carefully just copy the data for that variant.
This is a unfortunate for us since we use this pattern when byte swapping enums.
If we did nothing, it would mean that native-to-native swapping wouldn’t be a
no-op:
Why this happens is a rather unfortunate case of a missed optimization. It
never got merged due to fears of a potential performance regression and wasn’t
picked up. Hopefully these types of MIR-based optimizations can be revived
again, because without them we still might worry about reducing “LLVM bloat” to
improve compile times over writing idiomatic Rust.
// Avoid `Option::map` because it bloats LLVM IR.matchself.remove_entry(k){Some((_,v))=>Some(v),None=>None,}
Once the issue was identified the fix was simple enough. I’ve introduced a
method on ByteOrder which optionally maps a value in case the byte order
differs from Native ensuring that native-to-native swapping doesn’t do the
extra work dealing with each unique variant individually.
Conclusion
Congratulations on reading this far. I hope you’ve enjoying my explorations into
the zero-copy space.
If there’s anything you want to ask or comment on, feel free to post below or
on Reddit. Thank you!
It’s been a few months since I released Müsli to the world. An experimental
binary serialization framework. I’ve used it quite happily in a few projects.
But there was one area which it didn’t exactly fit.
Say you have a database, a dictionary with millions of text entries and cross
references. And you want to perform sporadic but fast word lookups on the
command line. How do you store the database?
We might opt to reach for some neat binary serialization. But even the fastest
framework takes seconds to load the data set, which just isn’t that great of a
user experience for a CLI tool. This is understandable, because the job of a
deserializer is broadly to take byte array and turn it into a data structure
that the Rust application can use. Typically this is done by painstakingly long walk
through the data and convert it to boxes or lists or other things that Rust
programmers can reason about.
For millions of text entries - those boxes, lists, and other things containing
millions of entries that need to be allocated, decoded, arranged, cuddled …
work that inevitably takes up resources we’d rather not spend.
This is where zero-copy serialization might come in handy. Instead of loading
and processing the entire contents of the file, we might be able to map the file
as-is into the application and treat it as Rust data structures directly. In
essence a &[u8] to &T translation layer. Take a slice, return a reference to
some type we can work with.
Now I can see the look on your face, isn’t that wildly unsafe?
Well yes. Of course it. Super duper unsafe1. But it doesn’t
have to be unsound.
In this article I’ll discuss what it takes to soundly map data directly onto
structures which are defined in Rust. And while doing so introduce a library I
spent the last couple of weeks working on to make that easier. Namely
musli-zerocopy.
There are two directions I want to discuss, soundly converting a data
structure into a a slice, and soundly converting a slice into the reference of
a data structure.
As a basis there are a few things we should know about &T.
The reference has to point to data which is aligned with respect to T;
All bytes in T except for padding (we’ll talk about this later) have to be
initialized to some value, and;
The bit pattern that is stores at &T has to be valid for T.
So if we take it in order. To convert a rust type into an slice we will have to
cover the topics of The #[repr(Rust)]
representation and alignment and
padding. After that when when we discuss
converting a slice back into a Rust type we also need to cover the notion of
legal bit patterns.
So… onwards!
The #[repr(Rust)] representation
Rust provides very few guarantees what the layout of a data structure should be.
While this might seem like a nuisance at first, it’s actually very helpful.
This is because #[repr(C)] is required to order the fields per their
definition order, and respect each fields alignment its alignment is the
multiple of a memory address that a specific structure wants to be located on,
and for u32 that is 4. To achieve this Rust moves the location of the number
field. This causes some extra unused space to be used in the struct called
padding.
Note An alignment is required to be a power of two, and Yoke itself
inherits the largest alignment of its fields which ensures that as long as
Yoke is aligned in memory, so too will number.
#[repr(Rust)] on the other hand is free to re-arrange the fields. Yoke might
be rewritten to this:
structYoke{number:u32,a:u8,b:u8,c:u8,d:u8,}
Which neatly means that the alignment of all the fields is respected, and we
save space.
In order to ensure that a data structure is valid, we can’t have Rust move
things around without telling us. So we’re obligated to use #[repr(C)]. To do
this correctly we need to delve deeper into the next topic. A tour into
alignment and padding.
So if we copy Yoke byte-by-byte, we will catch the value of _pad1 as well.
This causes a problem, because these values are not initialized.
First, padding bytes are considered uninitialized.
This is illustrated perfectly by our good friend Miri with this snippet:
usestd::slice;usestd::mem::size_of;#[repr(C)]structYoke{a:u8,number:u32,}fnmain(){letlink=Yoke{a:0x01,number:0x02030405,};letbytes=unsafe{letptr=(&linkas*constYoke).cast::<u8>();slice::from_raw_parts(ptr,size_of::<Yoke>())};// Touch the first byte in the padding between a and b.letb1=bytes[1];}
error: Undefined Behavior: using uninitialized data, but this
operation requires initialized memory
--> src/main.rs:21:14
|
21 | let b1 = bytes[1];
| ^^^^^^^^ using uninitialized data, but this
operation requires initialized memory
While Miri strictly speaking isn’t authoritative on all matters, it is right
here. So does this mean that there’s nothing we can do?
Well yes, we can initialize the padding ourselves. For example, directly where
Yoke is stored:
usestd::slice;usestd::mem::size_of;#[repr(C)]structYoke{a:u8,number:u32,}fnmain(){letmutlink=Yoke{a:0x01,number:0x02030405,};unsafe{letptr=(&mutlinkas*mutYoke).cast::<u8>();// Zero out three bytes of padding at offset 1ptr.add(1).write_bytes(0,3);}letbytes=unsafe{letptr=(&linkas*constYoke).cast::<u8>();slice::from_raw_parts(ptr,size_of::<Yoke>())};dbg!(&bytes);}
If that seems like too much, musli-zerocopy has a shorthand for the above
called
initialize_padding,
so the above becomes.
Deserialization seems easy in comparison. As long as we know that the buffer
we’re using is initialized.
But this is subtly wrong. As mentioned in the beginning &T has to reference a
T that is stored at an aligned memory location:
error: Undefined Behavior: accessing memory with alignment 2,
but alignment 4 is required
--> src/main.rs:12:25
|
12 | let link = unsafe { &*(&bytes as *const u8).cast::<Yoke>() };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| accessing memory with alignment 2,
| but alignment 4 is required
The nasty part here is that if we’re unlucky, we might’ve ended up loading
Yoke from an aligned memory address on the stack and wouldn’t notice this
issue with Miri.
So for deserialization we have at least the problem of alignment. Luckily we
have tools for that. Including this hack:
usestd::mem::size_of;#[derive(Debug)]#[repr(C)]structYoke{a:u8,next:u32,}// Align `T` with respect to `Yoke`.#[repr(C)]structAlign<T>([Yoke;0],T);fnmain(){letbytes:&Align<[u8;size_of::<Yoke>()]>=&Align([],[1,0,0,0,5,4,3,2]);letlink=unsafe{&*(&bytes.1as*constu8).cast::<Yoke>()};dbg!(&link);}
This stems from the fact that the alignment of the vector matches the largest
alignment of its elements. So even if the vector inside of Align is
zero-sized, it still forces the whole structure to be aligned by Yoke. Since
it’s zero-sized, we must conclude that the subsequent T is stored at the same
location, which luckily for us now is aligned by Yoke.
This is a neat hack. And I do use it in some places to store the output of
include_bytes! in an aligned buffer. But as a tool it is rather clunky. We
have to decide on the alignment up front at compile time.
If only there was a data structure that understand how to align its memory…
Ah well, that’s for later. First we need to convert another problem with
deserialization. What exactly constitutes a legal bit patterns for a
structure?
Legal bit patterns
Let’s revisit Yoke, but change the second field to be a char instead of a
u32. Of course we’ll also rename it, because otherwise it would be confusing.
If we try to cast a byte array into this structure, we need to make sure that
all bit patterns are inhabitable by it. But what bit patterns can a char
inhabit?
Reading the rust reference and char::from_u32 we can intuit that a char
is 4 bytes wide, but cannot inhabit all possible bit patterns that those 4 bytes
can represent.
|
5 | let c = unsafe { *(values.1.as_ptr() as *const u8).cast::<char>() };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
| constructing invalid value: encountered 0x00110000,
| but expected a valid unicode scalar value
| (in `0..=0x10FFFF` but not in `0xD800..=0xDFFF`)
This is how we’d define the legal bit pattern for any type T with a
#[repr(C)]:
Each field must be a legal bit pattern at their corresponding offsets.
If the type is an enum, there is a first secret field called the discriminant
which determines which variant is used. Then each field of the variant has
to have a legal bit pattern at their corresponding offsets.
Padding regions are ignored.
So let’s try to write a validator for Yoke which respects all these
requirements:
usestd::mem::{align_of,size_of};#[derive(Debug)]#[repr(C)]structYoke{a:u8,character:char,}#[derive(Debug)]enumError{NotAligned,BufferUnderflow,BadChar,}fnvalidate(bytes:&[u8])->Result<&Yoke,Error>{// Check that the buffer is aligned.if(bytes.as_ptr()asusize)%align_of::<Yoke>()!=0{returnErr(Error::NotAligned);}// Check that the buffer has the right number of bytes.ifbytes.len()<size_of::<Yoke>(){returnErr(Error::BufferUnderflow);}// Since the first field is an u8, it can inhabit *any* bit pattern.// Access the character field, at offset 4.letcharacter_ptr:*constu32=unsafe{bytes.as_ptr().add(4).cast::<u32>()};// Access the raw representation of character, which is a u32.letcharacter_raw=unsafe{character_ptr.read_unaligned()};// Test that the raw representation is a valid character.ifchar::from_u32(character_raw).is_none(){returnErr(Error::BadChar);}// We've inspected all fields and they've passed, so now we're good to cast the reference.Ok(unsafe{&*bytes.as_ptr().cast()})}structAlign<T>([Yoke;0],T);fnmain(){letdata=Align([],[42,0,0,0,80,0,0,0]);letlink=validate(&data.1);dbg!(link);}
That is… a lot. And we still have to align the buffer ourself.
Making it easier
The goal of musli-zerocopy is making the above work easier while providing
high level tooling like references, slices or even other collections to build
and interact with complex data structures with ease.
This is what it looks like:
usemusli_zerocopy::buf;usemusli_zerocopy::{Ref,ZeroCopy};#[derive(ZeroCopy)]#[repr(C)]structPerson{age:u8,name:Ref<str>,}letbuf=buf::aligned_buf::<Person>(include_bytes!("author.bin"));letperson=Person::from_bytes(&buf[..])?;assert_eq!(person.age,35);// References are incrementally validated.assert_eq!(buf.load(person.name)?,"John-John");
And this is the code that wrote author.bin:
usestd::fs;usemusli_zerocopy::{OwnedBuf,Ref,ZeroCopy};fnmain()->Result<()>{letmutbuf=OwnedBuf::new();// Insert an uninitialized value to ensure that the person data is// stored at offset 0.letperson=buf.store_uninit::<Person>();letvalue=Person{age:35,name:buf.store_unsized("John-John"),};buf.load_uninit_mut(person).write(&value);fs::write("person.bin",&buf[..])?;Ok(())}
This takes care of padding, alignment, and validation for most Rust types which
have a stable well-defined layout. We provide tools to easily build correct,
rich applications leveraging zero-copy data structures. It is really fast,
and should be memory safe (assuming there are no bugs or false assumptions from
my part).
I also want to emphasize the focus on incremental rather than up front
validation, which ensures that startup is fast and doesn’t needlessly consume
system resources. Incremental validation means that instead of validating the
whole structure in one go, we only validate the elements which are accessed,
like with buf.load(person.name)? above.
Tackling the dictionary
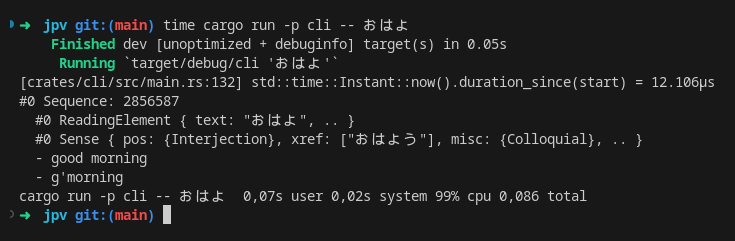
To loop back to what started me down this path, this is what the index of my dictionary
currently looks like using musli-zerocopy:
This project is also what needed map. So I’ve ported phf and hashbrown
(named swiss) to the project. The above uses swiss maps.
The index stores tens of millions of entries. Loading the same index using other
Müsli formats and validated rkyv takes a second or two while pinning a CPU
core to 100%, which actually isn’t fast enough for a CLI tool to feel
responsive.
The dictionary itself also uses a neat trick to perform string de-duplication,
by referencing subsets of already stored string by their prefix if they are
present. This in itself saves about 1G of space and I believe showcases what you
can accomplish when you have access to granular tooling:
letinput:Vec<(String,Id)>=/* .. */;letmutbuf:OwnedBuf=/* .. */;letmutlookup=HashMap::<String,Vec<Id>>::new();letmutexisting=HashMap::<_,usize>::new();letmutreuse=0usize;letmuttotal=0usize;for(index,(key,id))ininput.into_iter().enumerate(){ifindex%100000==0{tracing::info!("Building strings: {}: {key}",index);}total+=1;let(unsize,substring)=ifletSome(existing)=existing.get(key.as_ref()){reuse+=1;(Ref::with_metadata(*existing,key.len()),true)}else{letunsize=buf.store_unsized(key.as_ref());(unsize,false)};lookup.entry(unsize).or_default().push(id);if!substring{// Generate string prefixes and insert into existing map.for(n,_)inkey.char_indices(){letmuts=String::new();forcinkey[n..].chars(){s.push(c);if!existing.contains_key(&s){existing.insert(s.clone(),unsize.offset()+n);}}}existing.insert(key.into_owned(),unsize.offset());}}tracing::info!("Reused {} string(s) (out of {})",reuse,total);
I should note that construction of the dictionary is fairly time consuming,
but that doesn’t matter since it’s always done ahead of time.
With this and thanks to incremental validation in musli-zerocopy, querying
through the CLI is both instantaneous and fully sound:
So what about this other crate?
Since people are bound to ask how this crate relates to those. musli-zerocopy
actually occupies a similar niche to zerocopy, but is fairly dissimilar from
rkyv.
This is what I write in the crate documentation:
zerocopy doesn’t support padded types2,
bytes to reference conversions, or conversions which does not permit decoding
types unless all bit patterns can be inhabited by zeroes3. We still
want to provide more of a complete toolkit that you’d need to build and
interact with complex data structures like we get through the phf and
swiss modules. This crate might indeed at some point make use of
zerocopy’s traits.
rkyv operates on #[repr(Rust)] types and from this
derives an optimized Archived variation for you. This library lets you build
the equivalent of the Archived variant directly and the way you interact
with the data model doesn’t incur the cost of validation up front. With rkyv
it took my computer 100% of a CPU core and about half a second to load 12
million dictionary entries4, which is a cost that is simply not
incurred by incrementally validating. Not validating is not an option since
that would be wildly unsound - your application would be vulnerable to
malicious dictionary files.
zerocopy in particular deserves a massive shout out. joshlf has done
meticulous work documenting and upstreaming (!) layout guarantees which
benefits everyone in the ecosystem.
So I think, and I hope you agree that there is some space to carve out for a
more holistic toolkit which operates directly over #[repr(C)] types. If you
do, I invite you to take the project for a spin.
Recently I released Müsli to the world. An experimental binary serialization
framework. And the response so far has been great. Clearly there’s an interest
in improving the space.
Today I intend to dive into a specific topic I didn’t manage to complete before
release. And it is a big one. Error handling and diagnostics.
By the end of this post, I’ll show you a design pattern which can give you rich
diagnostics like this:
.field["hello"].vector[0]: should be smaller than 10, but was 42 (at bytes 34-36)
Which works for any Müsli format, has a small and easily optimized Result::Err
values, can be disabled with zero overhead, and provides full functionality in
no_std environments without an allocator.
Error handling seems fairly simple and given right? Rust has a Result<T, E>
which neatly implements the (unstable) Try trait so we can conveniently use
try expressions to propagate errors.
#[derive(Decode)]structObject{#[musli(decode_with=decode_field)]field:u32,}fndecode_field<D>(decoder:D)->Result<u32,D::Error>whereD:Decoder{letvalue=decoder.decode_u32()?;ifvalue>=10{returnErr(D::Error::message(format_args!("should be smaller than 10, but was {value}"))));}Ok(value)}
There are some of the caveats to this approach:
The return type gets bigger, and is something that needs to be threaded by the
Rust compiler all the way to the error handling facility.
Where is the message stored? This implies that D::Error stores it somewhere
(sometimes cleverly). If it’s stored in a Box<T>, it needs to allocate. If
it’s stored inline in the type using arrayvec all return signatures now
become larger by default.
How do we know that the error was caused by Object::field? Should the error
store the field name too? The name of the struct?
How do we know what input caused the error? Do we also have to store a data
location?
These are all workable problems. In fact, most serialization libraries
enriches the diagnostics produced somehow so that it’s more actionable.
Unfortunately I’ve found that you have to compromise between tight and complex
return values by putting everything in a box, or large error variants which have
a nasty habit of getting in the way of the compiler making things efficient.
Now say we want no_std without an allocator. Defining a rich error type is
starting to genuinely hurt - not to mention that it’s pretty much unworkable due
to its size.
structErrorImpl{#[cfg(feature="alloc")]message:String,#[cfg(not(feature="alloc"))]message:ArrayString<64>,// The index where the error happened.index:usize,}#[cfg(feature="alloc")]usealloc::boxed::BoxasMaybeBox;#[cfg(not(feature="alloc"))]structMaybeBox<T>{value:T,}structError{err:MaybeBox<ErrorImpl>,}
So in no_std environments without alloc you tend to compromise. Let’s look
at how a libraries provide diagnostics.
postcard is a no_std binary serialization format for serde, and
they’ve opted to reduce actionable diagnostics by only including error
variants. This means no location diagnostics, but it also means smaller error
types.
Well, I’ve had it with compromising. I want to try and fly a bit closer to the
sun and I’m bringing no_std with me.
The plan
In my Müsli announcement I tried to put emphasis on the experimental nature of
the framework. And the change I’m about to propose breaks the mold a little bit.
Maybe even a bit too much.
What I’ll propose is a model for:
Emitting dynamic errors and messages. Such as ones produces through
format_args!().
Errors can track complex structural diagnostics. Such as which byte offset
caused the error or even which field of a struct or index in an array caused
it.
All features are compile-time optional. Not by using features or --cfg
flags, but through generics. In a single project you can freely mix and match
which uses what. And you only pay for what you use.
The pattern works in no_std environments without an allocator, such as micro
controllers.
Sounds exciting right? To start things off I briefly want to touch on more
generally what it means to build abstractions in Rust that can melt away.
Abstractions that can melt away
Let’s imagine for a second we write a function like this to download a
collection of URLs:
Assuming that urls always contains some items, is there some way we can make
this function conditionally become a no-op depending on the implementation of
D? That is to say, Rust could correctly decide to remove most of the work.
Right now that doesn’t seem to be the case - we are obligated to iterate over
the input and somehow produce one Website instance for each url
provided1.
But with some minor changes we can build an abstraction that can be optimized
away, or in this case to the bare minimum of consuming the iterator2. We
make more elements of the function generic over the abstraction. Like this:
There’s obviously more than one way to do this, but with this particular trait
we can easily build a Downloader which demonstrably does very little. It
doesn’t even populate the vector. There is not even a vector.
What I hope to demonstrate is that with a bit of inversion of control we can
make it easier for Rust to prove that nothing is going on and simply remove the
code. Here by moving implementation details into the Downloader trait.3
Capturing errors
Let’s try and apply this idea to error handling by bringing back our friendly
decode_field function from above.
fndecode_field<D>(decoder:D)->Result<u32,D::Error>whereD:Decoder{letvalue=decoder.decode_u32()?;ifvalue>=10{returnErr(D::Error::message(format_args!("should be smaller than 10, but was {value}"))));}Ok(value)}
So what if we want to collect the error message without allocating space for the
string directly in the error being returned?
To collect it we’d first need somewhere to put it, so let’s introduce a trait
for it called Context.
traitContext{/// Report a message.fnmessage<T>(&mutself,message:T)whereT:fmt::Display;}
And as is appropriate, we now have to actually pass in an instance of a
Context that we can give our message to:
structError;fndecode_field<C,D>(cx:&mutC,decoder:D)->Result<u32,Error>whereC:Context,D:Decoder{letvalue=decoder.decode_u32()?;ifvalue>=10{cx.message(format_args!("should be smaller than 10, but was {value}"));returnErr(Error);}Ok(value)}
We’re already starting to get somewhere interesting. The error variant is now a
zero sized type, which reduces the return size as much as possible. But what
exactly is a Context?
Since it’s a trait the caller is responsible for providing an implementation. We
need it to somehow capture the reported message. One way to do it is to pack it
into an Option<String>.
Do you see what’s going on? All of our error handling and diagnostics -
regardless of what it is can be passed out through a pointer to the context.
This is why I call the pattern “abductive diagnostics”, because the context
argument effectively abducts the error from the function.
But it’s not for free. The cost we’ve imposed on our project is that the context
variable needs to be threaded through every fallible function which needs to
use it (something an effect system in Rust might someday remedy).
To improve on the cost / benefit of this pattern, let’s add more information to
the context:
traitContext{/// indicate that n bytes of input has been processed.fnadvance(&mutself,n:usize);}
And with that extend our Capture to keep track of this:
Now we can associate byte indexes to diagnostics. We’re really starting to build
out our capabilities!4 The neat part here is that we added some really
powerful capabilities to our system, while keeping the returned error a zero
sized type.
Next let’s see how this pattern can help us to capture errors without
allocating on the heap.
I was promised no allocations
Right now there’s clearly a String there, which uses allocations! It’s even
in the alloc crate.
This is true, but the neat part about having the context abduct our errors is
that we gain the necessary control to store them wherever we want.
So let’s build a context which stores errors on the stack instead using
arrayvec.5
One which stores errors and diagnostics on the stack, in NoStdContext.
But if you intend to integrate it into a strange environment you would very much
be encouraged to implement your own Context.
Restoring what was lost
If we pay attention to the method we refactored above, we might note that while
we gained the ability to abduct errors through the context, we lost two things
as well.
Regular errors which contains their own diagnostics can no longer be returned
if we wanted to; and
The method doesn’t guarantee that an error has been reported to the context
oops.
The latter is no good. When using regular error types we’re forced to somehow
produce an Error through some kind of constructor. Here we can just return the
marker type and in the worst case forget to provide a message.
So let’s address this by modifying Context further:
traitContext{/// The error type produced by the context.typeError;/// Add ways to construct a `Self::Error`.fnmessage<T>(&mutself,message:T)->Self::ErrorwhereT:fmt::Display;}
And the corresponding changes to decode_field looks like this:
fndecode_field<C,D>(cx:&mutC,decoder:D)->Result<u32,C::Error>whereC:Context,D:Decoder{letvalue=decoder.decode_u32()?;ifvalue>=10{returnErr(cx.message(format_args!("should be smaller than 10, but was {value}")));}Ok(value)}
Now the only way we can return from decode_field is by either producing
Ok(u32), or Err(C::Error). And the Context is the only one which can
produce C::Error’s, so we don’t accidentally return a blank error marker
without providing diagnostics.
In addition, do you remember that the Decoder also produces an error? The call
to decode_u32 doesn’t actually compile. We have to handle that somehow as
well. To do this, we extend our context further:
typeContext{typeInput;typeError;/// Add the ability to report an error that can be converted to `Input`.fnreport<T>(&mutself,input:T)->Self::ErrorwhereSelf::Input:From<T>;}
We can now specify the Input type as the deserializer error that the context
can abduct:
fndecode_field<C,D>(cx:&mutC,decoder:D)->Result<u32,C::Error>whereC:Context<Input=D::Error>,D:Decoder{letvalue=decoder.decode_u32().map_err(|err|cx.report(err))?;ifvalue>=10{returnErr(cx.message(format_args!("should be smaller than 10, but was {value}")));}Ok(value)}
Of course in the real implementation we just pass along the cx variable to
decode_u32. But this showcases how the pattern can be gradually introduced
into existing code which was of great help during refactoring.
What exactly the report implementation looks like I leave as an exercise to
the reader, but with these additions there are now two more interesting contexts
that Müsli provides:
Same which produces the same error (Context::Error) that it consumes
(Context::Input) providing full backwards compatibility.
Ignore which simply records that an error has happened, but returns a zero
sized marker type like before.
// Behaves just like the original version without `Context` support.letmutcx=Same::default();letvalue=decode_field(&mutcx,decoder)?;
// The error returned is a ZST.letmutcx=Ignore::default();letOk(value)=decode_field(&mutcx,decoder)else{// deal with the fact that something went wrong.};
Diagnostics
Error messages by themselves are cool and all, but what we really want is more
diagnostics. While it can be useful to know that something should be smaller
than 10, but was 42 this only helps us in the simplest cases to troubleshoot
issues. In most cases we don’t just need to know what went wrong, but where
it went wrong.
To this end we can add more hooks to Context. And this is where it starts
getting really interesting. In Müsli I’ve opted to add support for keeping track
of the byte index and fully tracing the type hierarchy being decoded.
So using one of the contexts (like AllocContext) provided above, we can
get error messages like this:
.field["hello"].vector[0]: should be smaller than 10, but was 42 (at byte 36)
Or even this, which includes the names of the Rust types which were involved:
Struct { .field["hello"] = Enum::Variant2 { .vector[0] } }: should be smaller than 10, but was 42 (at byte 36)
Or nothing at all! If you don’t use it, you don’t pay for it:
decoding / encoding failed
Conveniently our Encode and Decode derives fills out all these context
calls for you. So tracing is something you get for free6.
The cost of abstractions
I’m keenly aware that threading the context variable through the entire
framework can be a bit messy. It took me almost two days to refactor all the
code in Müsli. In the long run the ergonomics of it might simply pan out to not
be worth it, or we’ll try to change something to make it easier. For now I don’t
know what.
Luckily most users will not interact with the plumbing of the framework. They
should primarily focus on using the high level derives available. A smaller
number of users will end up writing hooks and that can be harder because there’s
a lot of things going on:
Two lifetimes, and three generics by default, and a strange Input parameter
for Context! Did I mention that Müsli is still an experimental project?
Still, I’m hoping to discover a better way of doing this from an ergonomics
perspective. If you have suggestions, I’d love to hear them!
Conclusion
Thank you for reading!
I can confidently say that with this, Müsli has the ability to produce state of
the art diagnostics with almost no effort from the user. I think most people
who’ve worked with serialization knows that without good diagnostics it can be
very hard to figure out what’s going on.
I will round off by displaying this error I’m currently plagued by, which is
caused by a binary format using serde. It’s actually the reason why I started
to pursue this topic:
Error: ../../changes.gz
Caused by:
invalid value: integer `335544320`, expected variant index 0 <= i < 11
I don’t know which field, in which struct, being fed what data, caused that
error to happen. Needless to say I’ll be switching that project to use Müsli.
The above certainly can be improved, and we can even add tracing to serde. But
not without compromises. And I want everything.
Website could support mocking. But maybe that’s not viable either. ↩
Since that is a legitimate effect we should preserve of calling the function. ↩
This isn’t something that comes for free, we now have to live with the
cognitive load of dealing with a weird interface. I think that most of the
time it might not even be worth it. ↩
The exact behavior of writing to an ArrayString at capacity is a bit
fuzzy, but at the very least anything that is outside of its capacity will
be drop. The exact boundary of which could be improved. ↩
I recently spent some effort trying to make reproto run in a browser.
Here I want to outline the problems I encountered and how I worked around them.
I will also provide a number of suggestions for how things might be improved for future porters.
A big chunk of the wasm story on Rust currently relies on stdweb.
Needless to say, this project is incredible.
stdweb makes it smooth to build Rust applications that integrates with a browser.
There’s a ton of things that can be said about that project, but first I want to focus on the porting efforts of reproto.
Getting up to speed and shaking the tree
The best way to port a library is to compile it.
For Rust it’s as simple as installing cargo-web and setting up a project with all your dependencies.
All it really needs is a Cargo.toml declaring your dependencies, and a src/main.rs with extern
declarations for everything you want compiled.
For reproto, that process looks like this:
# Cargo.toml
[package]
# skipped
[dependencies]
reproto-core = {path = "../lib/core", version = "0.3"}
reproto-compile = {path = "../lib/compile", version = "0.3"}
reproto-derive = {path = "../lib/derive", version = "0.3"}
reproto-manifest = {path = "../lib/manifest", version = "0.3"}
reproto-parser = {path = "../lib/parser", version = "0.3"}
reproto-backend-java = {path = "../lib/backend-java", version = "0.3"}
reproto-backend-js = {path = "../lib/backend-js", version = "0.3"}
reproto-backend-json = {path = "../lib/backend-json", version = "0.3"}
reproto-backend-python = {path = "../lib/backend-python", version = "0.3"}
reproto-backend-rust = {path = "../lib/backend-rust", version = "0.3"}
reproto-backend-reproto = {path = "../lib/backend-reproto", version = "0.3"}
stdweb = "0.3"
serde = "1"
serde_json = "1"
serde_derive = "1"
Interestingly enough, this is something I’ve touched on in a previous post as a portability concern.
In rustc-serialize, paths are not portable because not all platforms have serializers defined for them!
impls being missing for a specific platform wouldn’t be a big deal if platform-specific bits were better tucked away.
As it stands here, we end up with an incomplete impl Decodable which is a compiler error.
If the entire impl block was conditional it would simply be overlooked as another missing
implementation. In practice this would mean that you wouldn’t be able to serialize PathBuf easily, but this can be worked around be simply not using it.
Due to the current state of affairs, the easiest way to deal with it was simply to disable the default features for the num-* crates.
A bit tedious to add everywhere, but not a big deal:
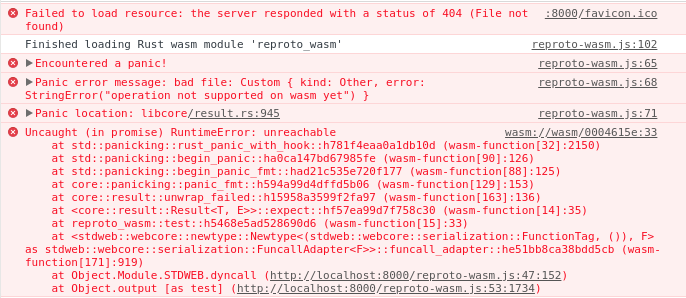
Taking this for a spin, would result in an unfortunate runtime error:
To work around this I introduced a layer of indirection.
My very own fs.rs.
I then ported all code to use this so that I can swap out the implementation at runtime.
This wasn’t particularly hard, seeing as I already pass around a Context to collect errors.
Now it just needed to learn a new trick.
Finally I ported all code that used Path to use relative-path instead.
This guarantees that I won’t be tempted to hit any of those platform-specific APIs like canonicalize, which requires access to a filesystem.
With this in place I can now capture the files written to my filesystem abstraction directly into memory!
Ruining Christmas with native libraries
Anything involving native libraries will ruin your day in one way or another.
My repository component uses ring for calculating Sha256 checksums.
The first realization is that repositories won’t work the same - if at all - on the web.
We don’t have a filesystem!
At some point it might be possible to plug in a solution that communicates with a service to fetch dependencies.
But that is currently not the goal.
This realization made the solution obvious: web users don’t need a repository.
I moved the necessary trait (Resolver) from repository to core, and provided a no-op implementation for it.
The result is that I no longer depend on the repository crate to have a working system, sidestepping the native dependency entirely in the browser.
Neat!
Revenge of the Path
I thought I had seen the last of Path. But url decided to blow up in my face like this:
error[E0425]: cannot find function `path_to_file_url_segments` in this scope
--> <registry>/src/github.com-1ecc6299db9ec823/url-1.6.0/src/lib.rs:1934:32
|
1934 | let (host_end, host) = path_to_file_url_segments(path.as_ref(), &mut serialization)?;
| ^^^^^^^^^^^^^^^^^^^^^^^^^ did you mean `path_to_file_url_segments_windows`?
error[E0425]: cannot find function `file_url_segments_to_pathbuf` in this scope
--> <registry>/src/github.com-1ecc6299db9ec823/url-1.6.0/src/lib.rs:2057:20
|
2057 | return file_url_segments_to_pathbuf(host, segments);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ did you mean `file_url_segments_to_pathbuf_windows`?
error: aborting due to 2 previous errors
error: Could not compile `url`.
Yet again. Paths aren’t portable.
The url crate wants to translate file segments into real paths for you.
It does this by hiding implementations of file_url_segments_to_pathbuf behind platform-specific gates.
Obviously there there are no wasm implementations for this.
An alternative here is to use something like hyper::Uri, but that would currently mean pulling in all of hyper and its problematic dependencies.
I settled for just adding more indirection and isolating the components that needed HTTP and URLs into their own modules.
"All problems in computer science can be solved by another level of indirection"
— David Wheeler
What’s the time again?
chrono is another amazing library, I used it in my derive component to detect when a string looks like a datetime.
error[E0432]: unresolved import `self::inner`
--> <registry>/src/github.com-1ecc6299db9ec823/time-0.1.39/src/sys.rs:3:15
|
3 | pub use self::inner::*;
| ^^^^^ Could not find `inner` in `self`
error[E0433]: failed to resolve. Could not find `SteadyTime` in `sys`
--> <registry>/src/github.com-1ecc6299db9ec823/time-0.1.39/src/lib.rs:247:25
|
/// snip...
error: aborting due to 10 previous errors
error: Could not compile `time`.
Because the derive feature was such a central component in what I wanted to port I started looking for alternatives instead of isolating it.
My first attempt was the iso8601 crate, a project using nom to parse ISO 8601 timestamps.
Perfect!
error[E0432]: unresolved import `libc::c_void`
--> <registry>/src/github.com-1ecc6299db9ec823/memchr-1.0.2/src/lib.rs:19:5
|
19 | use libc::c_void;
| ^^^^^^^^^^^^ no `c_void` in the root
error[E0432]: unresolved import `libc::c_int`
--> <registry>/src/github.com-1ecc6299db9ec823/memchr-1.0.2/src/lib.rs:21:12
|
/// ...
error: build failed
So nom depends on memchr, an interface to the memchr libc function.
That makes sense. nom wants to scan for characters as quickly as possible.
Unfortunately that makes nom and everything depending on it unusable in wasm right now.
In the following sections I try to summarize how we can improve the experience for future porters.
Make platform detection a first class feature of Rust
If you look over the error messages encountered above, you can see that they have one thing in common:
The are all unique.
This is unfortunate, since they all relate to the same problem: there is a component X that is hidden behind a platform gate.
When that component is no longer provided, the project fails to compile.
Wouldn’t it be better if the compiler error looked like this:
It works by detecting when your platform has a configuration which does not match any existing gates, providing you with contextual information of why it failed. This means that the matching would either have to be exhaustive (e.g. provide a default fallback), or fail where the matching actually occurs.
This is much better than the arbitrary number of compiler errors caused by missing elements.
Transitive feature flags
This is the first exercise I’ve had in explicitly disabling default features.
Sometimes it can be hard.
Dependency topologies are complex, and mostly out of your hand.
This suggestion is heavily influenced by use flags in Gentoo, and would be a controversial change.
The gist here is that I can enable a feature for a crate and all it’s dependencies.
Not just directly on that crate.
This way it doesn’t matter that a middle layer forgot to forward a feature flag, you can still disable it without too much hassle.
Different crates might use the same feature flag for different things.
But it begs the question: are we more interested in patching all crates to forward feature flags correctly, than we are patching crates which use the wrong flags?
Conclusion
This was a lot of work. But much less than I initially expected.
The wasm ecosystem in Rust is really on fire right now, and things are improving rapidly!
I’m actually really excited over how well it works.
Apart from a small number of expected, and even smaller number of unexpected dependencies.
Things just work.
In summary:
Avoid native dependencies.
When something breaks, it’s probably because of a gate.
Abstract the filesystem.
Avoid using Path/PathBuf and APIs which have platform-specific behaviors. Consider
relative-path as an alternative.
So to leave you, feel free to try out reproto in your browser using the new eval app:
UPDATE #1:
Here is the relevant PR in chrono to make time an optional dependency.
Please make your voice heard if this is something you want!
For nom, memchr support for wasmwas merged in December, unfortunately that leaves existing libraries behind until they are upgraded.